Temporary deployment scenarios (tear-down and multiple use)
The results of some automated deployment is temporary, and requires a tear down or clean up stage once it is no longer required. The behaviour of this usage differs depending on whether it is one client or multiple clients who are using the deployed resource.
Contents
Scenario
- The Client (such as an automation orchestrator, or a more basic client exposing automation controls) requests for a temporary automated deployment (i.e. it requires teardown).
- The Provider accepts the requests and starts the deployment
- When the deployment has completed the Client becomes aware of that, and triggers the intended usage of that deployment (e.g. automated tests)
- When the usage of that deployment has finished, the Client notifies the Provider that the deployed resource is no longer required
- The Provider tears down the deployed resource, at its convenience, to free up resources.
Example: One of the Amazon EC2 charging models is to charge per hour of uptime, so the longer the VM is deployed the more costs rack up. This is a strong reason for wanting to tear down at the end of use, compared to the traditional deploy of a build or similar which can sit on the machine until the next deploy occurs.
Standardisation options
1) One option would be to link from the autoResult to an autoPlan that, when executed, tears down the deployed resource.
Pros:
- v2 clients could consumer this, as long as they let the user choose any of the selection dialogs available for autoPlans.
- Could be used for other automation plans available as a result of this deployment, not just tear-down
Cons:
- Doubles the number of resources needed (or more)
2) Another option would be to add an additional state.
This state could either be:
- For the “ready”/”deployed” state, i.e. the “deployed and not torn down” state (so “completed” means “torn down”), or
- For the “torn down” state (so “completed” means “ready/deployed and not torn down”)
The client would then set the desiredState property to whatever the final state was (“completed” for the first option, or “torn down” for the second option) when it has finished with the deployed resource.
Pros for the new ready/deployed state would be that “completed” is still the final state.
Pros for the new “torn down” state would be that where v2 clients use “completed” as the trigger for the next automation execution (e.g. executing tests on the deployed resource) the behaviour remains the same.
Pros for using an additional state over a separate plan: it better models the state of the deployed resource - its state is available from a single autoResult, not two separate ones.
3) An extension of option (2) would be to provide more means for providers to define the semantics of their custom states.
e.g:
- A way to flag which states are “final” (which would be used in place of checking for completed/cancelled)
- A way to indicate which states can be set as the “desiredState” (based on what the current state is)
- Some way to indicate to orchestrators which states mean that control is passed back to them (i.e. all “final” states, plus the “ready/deployed” state)
- Perhaps also some way to indicate to workers the relationship between states and their control.
Pros of this custom state semantics approach:
Cons:
- Drastically increases complexity (so clients & providers are less likely to implement it, which reduces its usefulness as a standard)
- Might end up being too specific, making some desired implementations unachievable
- May be prone to differing interpretations, which significantly impairs interoperability
Extended scenario: multiple-client use of deployed resource
Once the resource has been deployed other Clients, or other users or resources on the same Client, could notify the Provider that they are using (or have a “using interest”) in that deployed resource, and the Provider will only tear it down after they have all finished using it.
The initial Client who requested the deployment could include a property on the request, which should be mirrored on the result, whether they intend the deployment for single-Client use or for shared use.
- Client 1 creates a request, and either:
- Client 1 indicated that it was sharable, or
- Client 1 did not indicate a sharing preference and the Provider’s default is to allow sharing
- The Provider does the deployment
- Client 2 sees the result, and that it has been deployed and not torn down, and that it is sharable, and that it wants to use it
- Client 2 informs the Provider that it is using that result (registers itself as an interested party)
- Client 1 finishes with the deployed resource and notifies the provider of this
- The Provider does NOT tear down the deployed resource
- Client 2 finishes with the deployed resource and notifies the provider of this (deregisters itself as an interested party)
- The Provider tears down the deployed resource (immediately or at a later time)
Effect on standardisation options
Effect on option 1)
Pros:
- If there are multiple clients who have registered an interest in this result, then for all except the last client the linked “undeploy” autoPlan merely removes them from the interested parties list.
Effect on options 2) and 3)
- There’s a minor issue that once Client 1 indicates that they are finished by setting the desiredState to “torn down” (or whatever the final state is) it will sit in that state until all the interested parties have deregistered. (See point 2 in “Extended option 2”). However, maybe that is an appropriate way of showing that the deployed resource is in a state of “will be torn down when all interested parties deregister”.
Mechanism for registering interest
A partial update (see PATCH) on automation result to add a URL representing itself to a collection of “interestedParties”. That URL is arbitrary from the Provider’s point of view, but must be under the control of the Client (i.e. under the client’s domain name) in such a way that it is unique across clients. For clients who are not accessed themselves via a URL, they could use their IP address on their local network with a UUID appended, e.g. http://10.0.0.1/f81d4fae-7dec-11d0-a765-00a0c91e6bf6 (although it would be better if this were not an http URI, but something like the tag: scheme or urn: instead).
If the client sends an initial request without specifying whether or not it is sharable, the Provider default is used. I would suggest the default should be to allow it to be sharable for most cases (but some providers may have specific cases).
Extended option 2)
When shutting down:
- Client 1 sets the desiredState property to the final state (e.g. “torn down”)
- If it receives a 2xx return code, then it should consider its request accepted. Only if it really wants to wait until the teardown is finished should it poll the actual state, otherwise it should just consider the deployed resource gone.
- The Provider keeps the result in the state that indicates it is deployed and not torn down, and keeps the desiredState as the state set by Client 1.
- Client 2 removes itself as an interested party
- The Provider sees that it has a deployedState indicating that tear down is requested, and there are no interested parties registers, so tears down the deployed resource.
Note that the clients act differently depending on whether they were the client who created the request, or a client who discovered an existing result to use. This is a benefit as it allows the “interested parties” behaviour to be optional on the client-side. Clients who do not implement that behaviour can still create requests, and can still request them to be torn down when they have finished with them. However, they must understand that they ought to check the response code of the PUT they used to set the desired state rather than polling to wait for the actual state to change.
We suggest the extended option (2).
Extended scenario: tear-down of orchestrated/composed deployment
This section is to discuss how tear-down works when the deployment is composed of multiple automation plans, with arbitrary dependencies between them, possibly from multiple providers.
This scenario is likely to only work if all the component plans have the ability to be torn down.
The orchestrator should know how to tear down the component plans that it set up.
However, the problem comes when another client registers that it is using
one of those component auto results that the master plan set up.
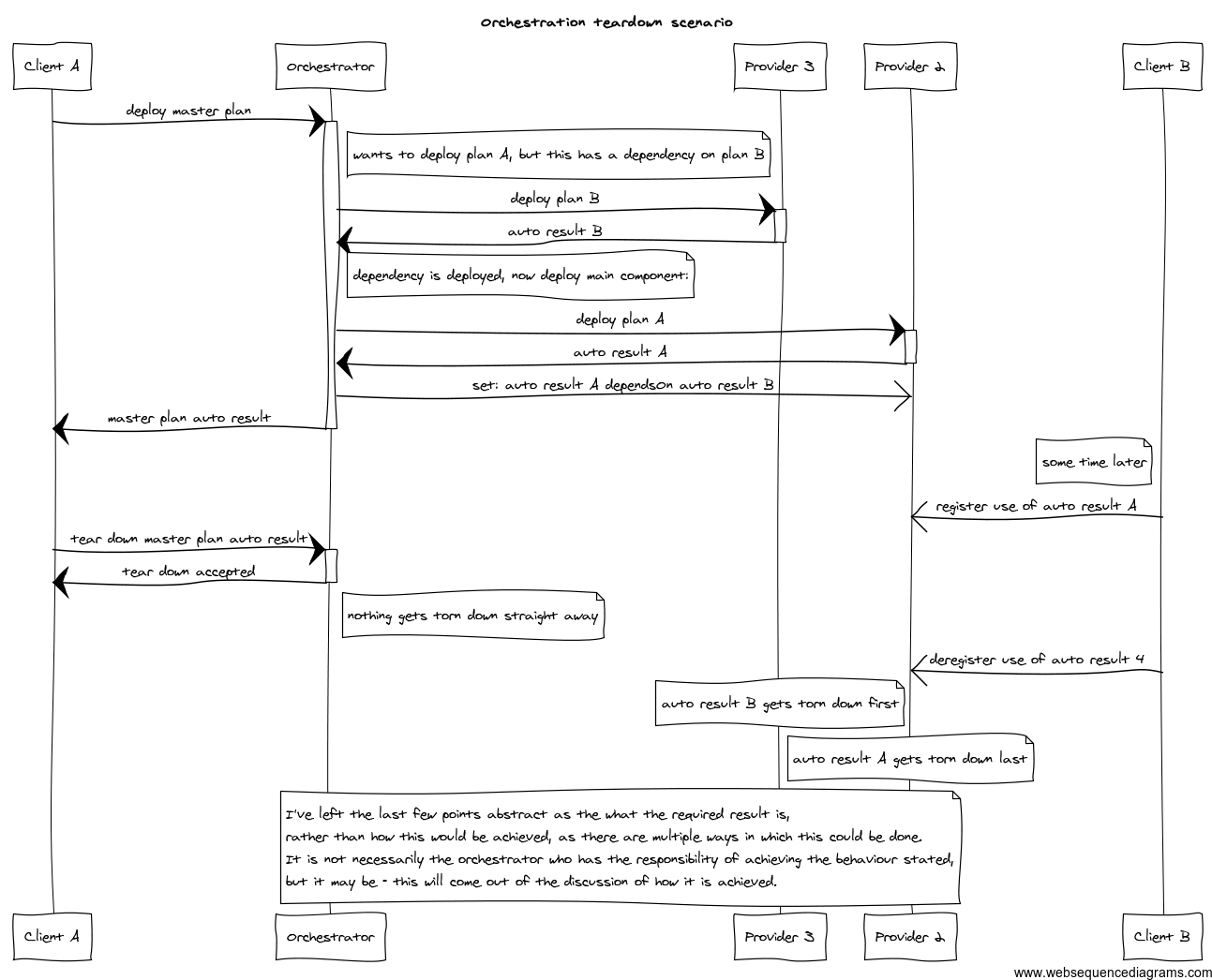
So the problem scenario goes something like this:
- Client A asks provider 1 (the orchestrator) to deploy the master plan.
- Provider 1 (the orchestrator) wants to start auto plan A on provider 2,
but that has a dependency on auto plan B on provider 3
- (the fact that auto plan B is used to fulfil this dependency is most
likely controlled by the orchestrator, and may be represented in auto
plan A as in the Automation plan configuration data scenario or may
not be represented there at all and may be the result of manual
configuration in the master plan).
- The orchestrator asks provider 3 to start auto plan B, which results in
the creation of auto result B.
- When that has completed, the orchestrator asks provider 2 to start auto
plan A, which results in the creation of auto result A.
- The orchestrator somehow marks that auto result A dependsOn auto
result B. (Exactly how this happens can be discussed.)
- The orchestrator may or may not have needed to pass in information
from auto result B, depending on the nature of the dependency.
- Another client, client B, sees auto result A and registers itself as
a user of that result.
- Some time later:
Client A indicates to the orchestrator that it is finished with the
master plans result, so it can be torn down.
- The orchestrator performs its tear down procedure, with the following
results:
- Auto result A (the main component, which depends on auto result B, and
which client B is using) should not get torn down until client B has
indicated that it is finished (i.e. deregistered its interest)
- Auto result B (the dependency) should not get torn down until auto
result A has been torn down (i.e. has finished it) because of the
dependsOn relationship form auto result A.
I’ve left the last few points abstract as the what the required result is,
rather than how this would be achieved, as there are multiple ways in
which this could be done. It is not necessarily the orchestrator who has
the responsibility of achieving the behaviour stated, but it may be - this
will come out o the discussion of how it is achieved.
(In this diagram I’ve treated the create request/lookup result actions as synchronous, when in reality they are not (or are not necesserily), in the hope that this more simply communicates the intent of the diagram.)
One particular thing to consider is mixes of OSLC automation spec versions
implemented by the different clients and providers (although anyone using
or providing tear down must be using v3) and also if areas/profiles/modules of the spec
(like supporting or consuming multi-use, or supporting or querying the
dependsOn property) are optional, then can this scenario still work with
certain providers unaware of those behaviours? (e.g. it would be
preferable if any providers could be used by an orchestrator, even if they
do not support dependency mapping - although I’m not sure if this is
possible. Hopefully all providers would support tear-down if it makes
sense in their product’s area.)
Issues
- Distinguishing which results must be torn down when finished, which can be torn down but don’t need to be, and which can’t.
- Should the initial requesting client (or any other client) be able to force a shutdown irrespective of the interested parties list?
- They could probably do this by clearing the interested parties list themselves, then tearing down as usual. Therefore we should allow any client to remove any entry in this list, or alternatively provide a “force tear down” option somehow.
- Note that other clients (e.g. orchestrators, managers) who may want to tear the deployed resource down will be subject to the same constraints as the initial requesting client. That is, it will not be shut down until the interested parties list is empty.
- Dealing with clients that register as an interested party (or create a request) then never deregister themselves (e.g. crash or hang).
- Perhaps have a timeout? Clients could provide their own timeout (up to a Provider-specified maximum) or the Provider could have a default. Clients could increase their timeout periodically if they are still using it, allowing them in total to go beyond the Provider-specified maximum.
- The term “interested party” might be too vague, because it is specifically clients that are using the deployed resuorce, not all who have an interest in it (e.g. there might be some who are interested in being notified when it is torn down, but are not actively using it). Perhaps “inUseBy” is a better name for the relationship.
If the Provider is charging the Client based on its usage of the deployed resource, then the charging should probably stop at the point the teardown is requested, not the point at which it is torn down. i.e. generic providers should probably record when the clients no longer require the deployed resource, in case other components are calculating cost.
Consumer registration of interest mechanism. Proposals include:
- A new resource created by consumers (TODO: poll other workgroups for common/similar need)
- Consumer updates automation result
- A compromise, where consumers update the automation result (as in the 2nd proposal) with a URI that may or may not be a link to the new consumer-resource (as in the 1st proposal). We could say that providers MAY enforce a restriction on the range of the property in the automation result such that it must point to a consumer-resource, if the provider requires other properties on that resource.
- Others?
- Expiration of deployed resources
- Determining when a set of deployed resources can be safely torn down
- provider-to-provider or deployed resources-to-deployed resource relationship (dependsOn) modelling
- What to do about tearing down a composite/orchestrated deployment if not all of the component plans’ providers support teardown? Leave it up to the orchestrator to decide?



