This wiki is locked. Future workgroup activity and specification development must take place at our new wiki. For more information, see this blog post about the new governance model and this post about changes to the website.
Resource Creation
Conventional REST wisdom holds that resource creation is generally a simple task. In most cases, you POST a document to a URL. The most likely response codes are 201, indicating a successful creation (including the URL of the newly created resource) or a 400 error of some kind indicating that the creation failed. However, in many cases, we can not assume that the client has enough data to ensure successful creation of the resource. In particular, imagine where a user in a quality management tool wants to create a record in a defect tracking system or a requirements management system. In most systems, resources like work items, change requests, and requirements are all highly configurable with required attributes and other associated process rules. Under these circumstances, there are two ways that a client could know how to create a well-formed resource:- It could read a description of the acceptable shape of these resources and the associated process rules. Currently, none of these systems have compatible schema systems, type systems, or process rules.
- We could agree, in advance, that a certain format is definitionally acceptable for a certain resource type. Any differences between the agreed-upon resource format and the rules of the underlying storage mechanism would be the responsibility of the OSLC implementation to sort out.
- Client needs an API to create a certain kind of resource.
- Client tool may want the URI of the resource to be created. This may be found at POST time, or at a later time.
- Loosening this requirement, we could say that the foreign tool needs a way of finding the resource that was created. If the foreign tool can be expected to understand the server’s query mechanism, it might use query to find this resource. However, that is only viable if the client put data in the resource making it uniquely identifiable. In the case of (eg) a test case referencing a defect, many test cases may be referenced by the same defect, making such a query ambiguous. Also, failing to include the capability to find resources created through this protocol introduces a dependency on the query capability.
- Client tool MAY know more about the server in which the resource is being created, and in those cases should be able to create the resource without user intervention.
- Agree on the format that will, definitionally, be accepted as a POST; (Any differences between the agreed-upon resource format and the rules of the underlying storage mechanism would be the responsibility of the OSLC implementation to handle).
- Standardize the way that we describe the shape of a valid resource so the client can learn what is needed in advance of the POST; (Currently, most of these systems have incompatible schema systems, type systems, or process rules);
- Standardize a response document that explains the problems with an invalid POSTed document, allowing a client to discover how to make a resource valid after the POST fails;
- Have the server accept the data even if it is bad, return a “regular” URL on that data (one that will always be associated with this resource).
- Say that we do not use POST in these cases – client will always GET a Web UI (possibly with seed data) that allows the user to create the resource;
- Standardize a way for the client to handoff creation of the resource to the tool that already knows how to create the resource, while retaining its URL.
Unattended Resource Creation
This is a fairly simple interaction – the client POSTs the agreed-upon resource format to the factory URL, and receives 201 (Created) along with the URI of the newly minted resource. This is the traditional RESTful Resource Creation.Attended (or delegated) Resource Creation
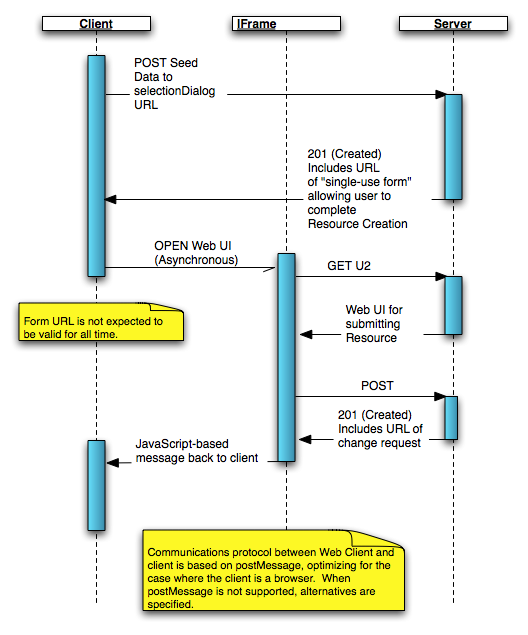
The drafts mechanism in RTC achieves attended resource creation, although it did so by introducing some concepts specific to its implementation (in particular, the notion of the draft workitem). This concept is not easily implementable in other systems, however. Here is the proposal for the attended resource creation protocol:- Client POSTs a resource “stub” – typically a subset of a predefined resource format – to a factory URL on the server. It may be helpful to view this as a "form factory" rather than as a "resource factory."
- This URL is likely provided as part of a configuration step, connecting the client to the server.
- This URL likely identifies a context to the server, including details that we don’t want to require the client to be aware of, such as the RTC Project Area or CQ User Data Base.
- The server returns 201 (Created) along with the URI of a form which, when opened in a browser, allows a user to complete the data entry process, resulting in a well-formed resource. This form is an HTML resource that includes Java Script to communicate the URL of the created change request back to the client. The protocol for this communication is documented as part of the OSLC-CM 1.0 Delegated Resource Selction and Creation spec.
-- SteveAbrams - 05 Feb 2009


| I | Attachment | Action | Size | Date | Who | Comment |
|---|---|---|---|---|---|---|
| |
Resource_Creation.png | manage | 71.3 K | 28 May 2009 - 15:29 | SteveAbrams | Attended Reource Creation Interaction Diagram |
{kind=link}
Topic revision: r5 - 28 May 2009 - 15:32:45 - SteveAbrams
|
|
Contributions are governed by our Terms of Use
Ideas, requests, problems regarding this site? Send feedback